Quickstart DDPM: Train a model that adds glasses to a face
Download the Dataset
Download the dataset (3.3 Gb), unzip it, place it in the datasets directory, and create your checkpoints directory:
wget https://www.joligen.com/datasets/noglasses2glasses_ffhq.zip
unzip noglasses2glasses_ffhq.zip
mkdir datasets
mv noglasses2glasses_ffhq datasets/noglasses2glasses_ffhq
rm noglasses2glasses_ffhq.zip
mkdir checkpoints
This dataset contains two subdirectories with portraits: one with glasses, one without glasses. Only the dataset of faces wearing glasses (trainB) is used here. For every face with glasses, there's a corresponding mask location of the glasses. Thus this is a paired dataset: face with hidden glasses on one side, same face with glasses on the other side.
Train your Diffusion Model
We train a DDPM with joliGEN palette model (https://arxiv.org/abs/2111.05826) with mask conditioning to add glasses from human's faces.
Use train.py along with the example joliGEN config file
to launch the training:
python3 train.py --dataroot datasets/noglasses2glasses_ffhq --checkpoints_dir ./checkpoints/ --name noglasses2glasses --output_display_env noglasses2glasses --config_json examples/example_ddpm_noglasses2glasses.json
You can follow your training evolution right from your terminal. Lines
like this one will be printed (according to the --output_print_freq
option, which is set to 384 iterations in this example, we recommend
setting its value to at least train_batch_size * train_iter_size to
have smooth curves):
(epoch: 1, iters: 384, time comput per image: 0.019, time data mini batch: 0.002) G_tot_avg: 0.177608
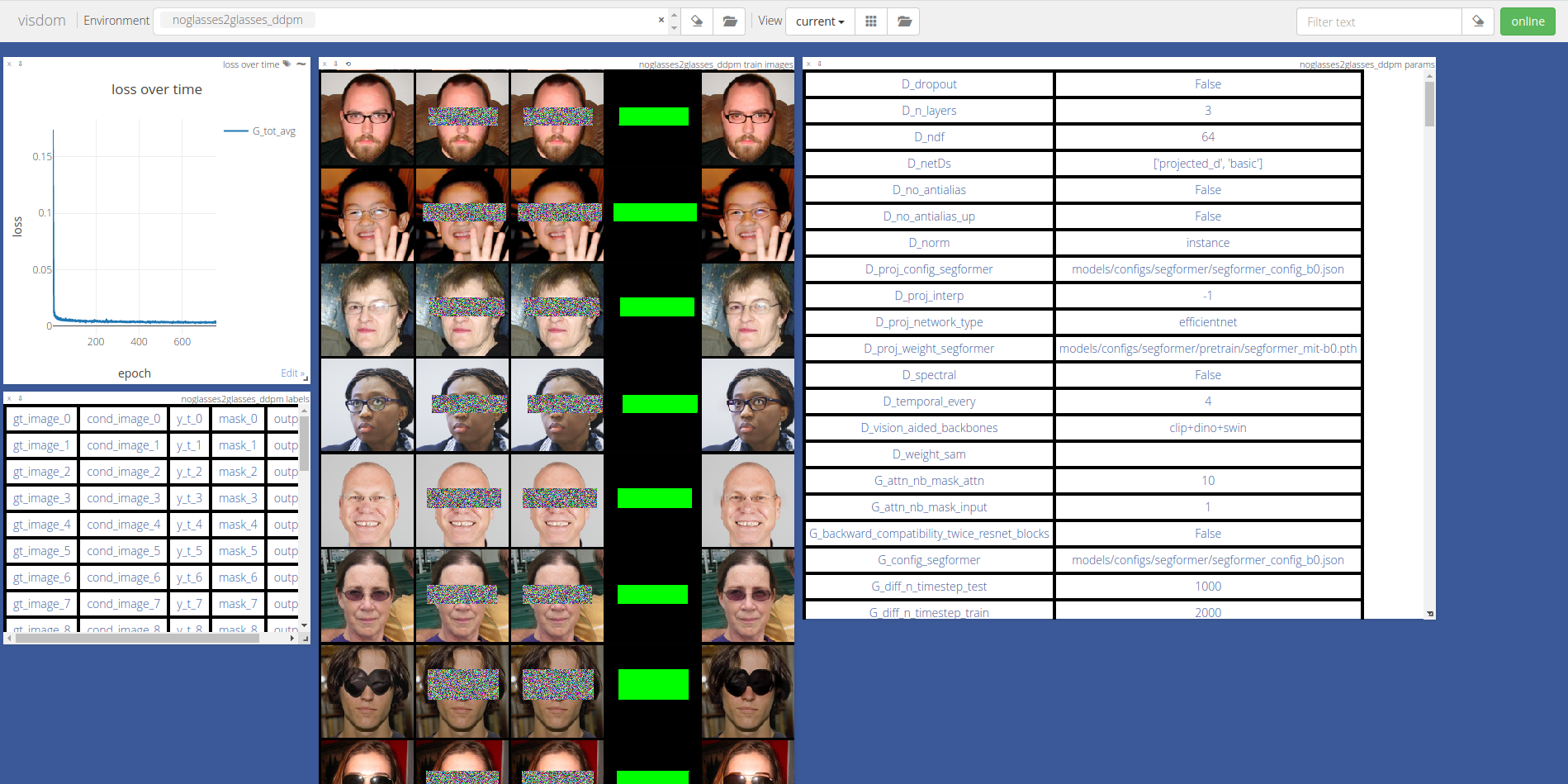
Alternatively, you can monitor your training through a local web page to which training logs are sent.
The DDPM converges in around 20 hours on a single Titan X (Pascal architecture), after training for ~68 epochs with batch size 8, iter size 16, equivalent to a full batch size of 128.
DDPM Training Visualization
Open http://localhost:8097/env/noglasses2glasses (or alternatively
http://<your-server-address>:8097 to have a look at your training
logs: loss curves, model output and inputs, and the options used to
train.